Introdução¶
O que é Libs?¶
Libs é o novo ambiente computacional e de documentação que vem sendo concebido para os modelos de otimização energética do CEPEL (NEWAVE, DECOMP, DESSEM, GEVAZP, PREVIVAZ e SUISHI), utilizados oficialmente para o planejamento da expansão, planejamento da operação, despacho energético e formação do preço de energia para o sistema brasileiro. Todas as novas funcionalidades nos modelos da cadeia estão sendo desenvolvidas de maneira uniforme para os modelos neste novo ambiente, que utiliza técnicas no estado da arte em termos de estrutura de dados, interface com o usuário, programação e execução.
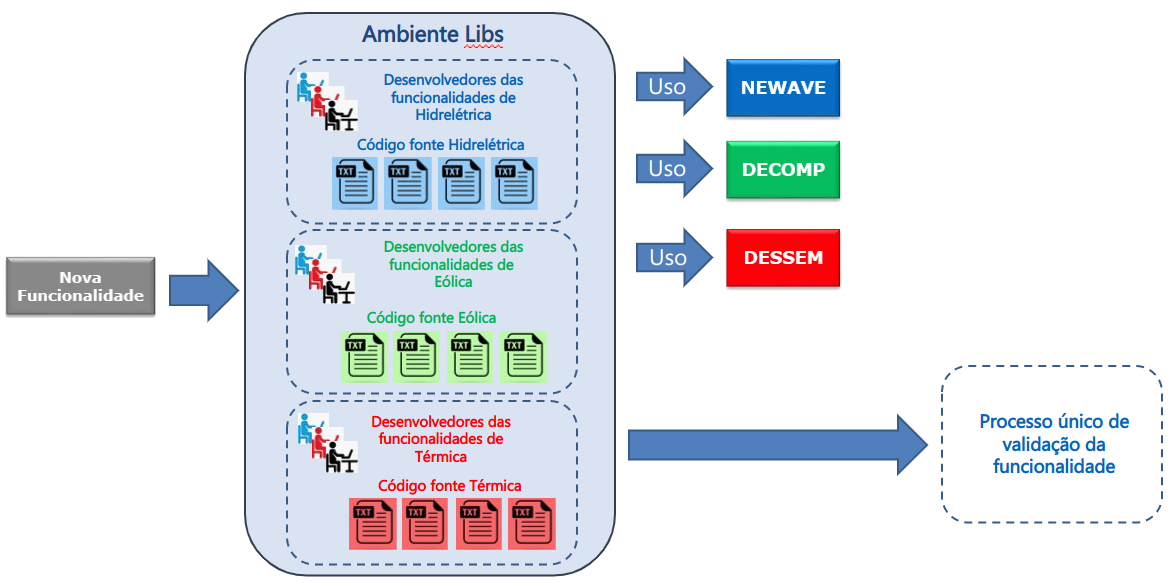
As funcionalidades já presentes nos modelos também estão sendo progressivamente implementadas para uso de forma alternativa através das bibliotecas deste novo ambiente. O objetivo é não só preservar as modelagens e metodologias desenvolvidas até hoje, mas também proporcionar a portabilidade, para todos os modelos (quando aplicável e conveniente), de alguns aspectos do problema de planejamento, como por exemplo:
representação individualizada das usinas hidrelétricas, modelagem DC da rede elétrica e restrições de unit commitment térmico;
representação de incertezas nas vazões afluentes às usinas hidrelétricas e na geração eólica;
estratégias de solução para resolver os diversos tipos de problema, como programação dinâmica dual estocástica e PL/MILP único.
Como resultado, há um ganho de flexibilidade na representação do sistema, discretização temporal a ser adotada (horária, semanal ou mensal), horizonte de estudo considerado (semanas, meses ou anos). e estratégia de resolução aplicada aos problemas associados aos diversos níveis de planejamento de sistemas hidrotermo-eólicos.
O ambiente computacional Libs visa atingir e ampliar os objetivos já atingidos pela cadeia atual de modelos utilizada oficialmente para o planejamento da expansão, planejamento da operação, despacho energético e precificação da energia (NEWAVE, DECOMP, DESSEM), porém em um novo ambiente computacional.
Componentes das Libs¶
Libs é composto por diferentes módulos que se interligam. Como o nome sugere, é formado por conjuntos de “bibliotecas” para programação das diversas funcionalidades, e que podem ser combinadas para utilização em três formatos: programas executáveis, interface gráfica e bibliotecas para acesso através de scripts (API). Com isso, busca-se atender aos mais diferentes tipos de usuário: os que preferem edição e visualização direta de arquivos texto, os habituados a manuseio de janelas para preenchimento de dados e análise de resultados, e aqueles que preferem trabalhar com alguns níveis de automação dos processos, utilizando scripts padrões ou personalizados.
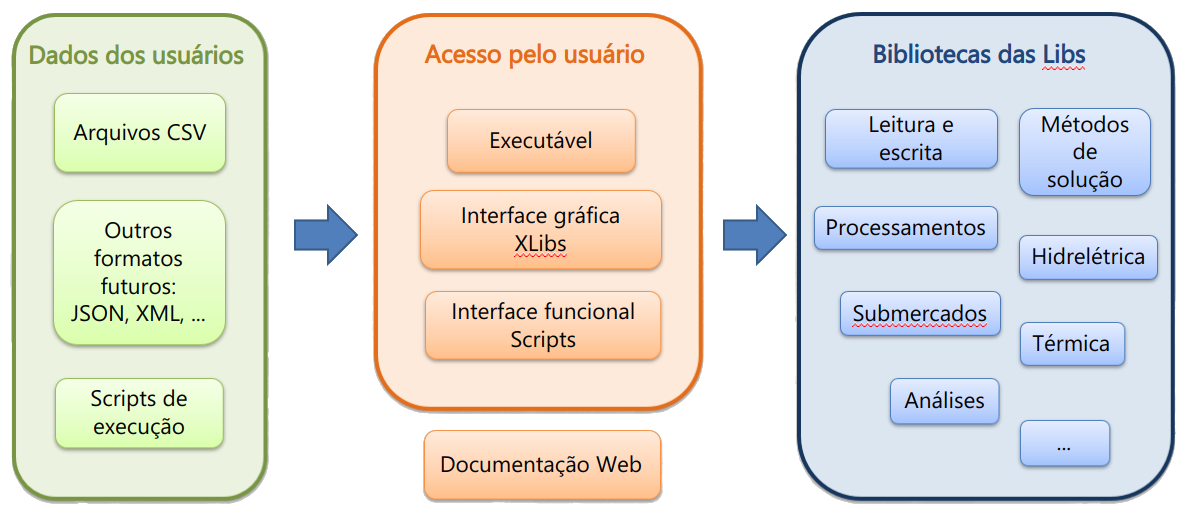
Sendo um ambiente uniforme para todos os modelos - respeitadas as diferenças temporais entre as aplicações - possibilita-se uma padronização dos dados de entrada, de saída, das funcionalidades dos modelos matemáticos e das interfaces gráficas. Essa unicidade traz diversas vantagens, com destaque para:
padronização dos dados de entrada , que podem ser reaproveitados entre os diferentes horizontes de estudo;
padronização dos dados de saída, facilitando a visualização pelo usuário, a automatização de leitura e a integração entre diferentes execuções do programa;
unificação das interfaces gráficas para tratamento dos dados, sendo voltadas por funcionalidade e não por modelo;
flexibilidade para utilização das diversas funcionalidades deste ambiente nas diferentes discretizações temporais, se pertinente.
Estrutura de Arquivos e Dados de entrada¶
Inicialmente, o formato utilizado para os dados de entrada é baseado em arquivos CSV, por ser um formato usualmente utilizado para fornecimento de dados e facilmente editado em diversas ferramentas existentes, como o Google Sheets ou o Microsoft Excel®.
Arquivos formato CSV¶
O arquivo de entradas das Libs possuem características comuns ao formato CSV. Esses arquivos seguem as seguintes premissas:
Linhas que começam com “&” são consideradas comentários e não são lidas pelo modelo.
Linhas em branco são desconsideradas
Cada linha representa um dado com vários campos associados.
Os campos são separados pelo caractere separador “;”.
Cada campo contêm um único dado.
O primeiro campo de cada linha é SEMPRE um identificador do dado que determina também quantos e quais dados vem nos campos subsequentes.
Arquivo Índice¶
O arquivo índice contêm uma lista de funcionalidades a serem consideradas através do ambiente LIBs, através das seguintes informações: nome da funcionalidade a ser ativdada; descrição da funcionalidade (a critério do usuário); nome do arquivo onde se encontram os dados relacionados à funcionalidade.
Em cada linha do arquivo os campos são os seguintes:
Campos |
Obrigatorio |
Nulável |
Descrição |
|---|---|---|---|
IDENTIFICADOR-FUNCIONALIDADE |
Sim |
Não |
Identificador referente a funcionalidade que deve ser considerada |
Descrição |
Não |
Não |
Descrição da funcionalidade, do arquivo ou qualquer outra informação relevante para o usuário. Esse campo não é utilizado. |
Arquivo com os dados para determinada funcionalidade |
Sim |
Não |
Caminho para o arquivo com os dados. Pode ser fornecido de forma absoluta ou relativo ao diretório do arquivo de índices. |
Campos |
Tipo |
Unidade |
Mínimo |
Máximo |
Padrão |
|---|---|---|---|---|---|
IDENTIFICADOR-FUNCIONALIDADE |
Texto |
||||
Descrição |
Texto |
||||
Arquivo com os dados para determinada funcionalidade |
Texto |
Exemplo de utilização:
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente à funcionalidade que deve ser considerada
& Descricao: Descrição com para o campo 2
& Caminho: Caminho para o arquivo com os dados.
& Pode ser fornecido de forma absoluta ou relativo ao diretório do arquivo de índices.
&*****************;**********;****************************************
&ID ;Descricao ;Caminho
&- ;- ;-
&SSSSSSSSSSSSSSSSS;SSSSSSSSSSSSSSSSSSSSSSSS;SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS
EOLICA-CADASTRO ;Modelagem Usinas Eolicas;dados_eolicas.csv
ID-FUNCIONALIDADE2;Descrição2 ;dados_funcionalidade_2.csv
ID-FUNCIONALIDADE3;Descrição3 ;/caminho/absoluto/dados_funcionalidade_3.csv
Observações:
Diversas funcionalidades podem conter seus dados em um único arquivo, bastando copiar o nome do arquivo para estas funcionalidades. De qualquer forma, recomenda-se manter os dados em arquivos separados para melhor organização e reaproveitamento de dados, e também para manter uma estrutura de colunas única para cada arquivo CSV.
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente a funcionalidade que deve ser considerada
& Descricao: Descrição com para o campo 2
& Caminho: Caminho para o arquivo com os dados.
& Pode ser fornecido de forma absoluta ou relativo ao diretório do arquivo de índices.
&*****************;**********;****************************************
&ID ;Descricao ;Caminho
&- ;- ;-
&SSSSSSSSSSSSSSSSS;SSSSSSSSSS;SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS
ID-FUNCIONALIDADE1;Descrição1;todos_os_dados.csv
ID-FUNCIONALIDADE2; ;todos_os_dados.csv
Arquivos de dados¶
Cada item no arquivo de índices aponta para um outro arquivo contendo os dados referentes à funcionalidade associada. Esses arquivos de dados terão as mesmas premissas descritas para o arquivo de índices, com exceção do número de colunas de dados, que pode variar de acordo com cada dado.
Dessa forma imagine as funcionalidades de identificador “FUNCIONALIDADE-UM” e uma outra funcionalidade com identificador “FUNCIONALIDADE-DOIS”. FUNCIONALIDADE-UM possui os dados “DADO-UM-FUNCIONALIDADE-UM” e “DADO-DOIS-FUNCIONALIDADE-UM”, e a FUNCIONALIDADE-DOIS posui os dados “DADO-UM-FUNCIONALIDADE-DOIS” e “DADO-DOIS-FUNCIONALIDADE-DOIS”.
Assim, para a situação acima um arquivo de índices possível seria:
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente a funcionalidade que deve ser considerada
& Descricao: Descrição com para o campo 2
& Caminho: Caminho para o arquivo com os dados.
& Pode ser fornecido de forma absoluta ou relativo ao diretório do arquivo de índices.
&******************;**********;****************************************
&ID ;Descricao ;Caminho
&- ;- ;-
&SSSSSSSSSSSSSSSSSS;SSSSSSSSSS;SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS
FUNCIONALIDADE-UM ;Descrição1;dados_funcionalidade_um.csv
FUNCIONALIDADE-DOIS;Descrição2;dados_funcionalidade_dois.csv
Seus respectivos arquivos de dados seriam:
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente a funcionalidade que deve ser considerada
& Campo1: Descrição para o campo 1
& Campo2: Descrição para o campo 2
& Campo3: Descrição para o campo 3
&**************************;**********;**************;*************************
&ID ;Campo1 ;Campo2 ;Campo3
&- ;- ;- ;-
&SSSSSSSSSSSSSSSSSSSSSSSSSS;IIIIIIIIII;FFFFFFFFFFFFFF;SSSSSSSSSSSSSSSSSSSSSSSSS
DADO-UM-FUNCIONALIDADE-UM ; 1; 1.0;Nome_Exemplo1
DADO-UM-FUNCIONALIDADE-UM ; 2; 2.0;Nome_Exemplo2
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente a funcionalidade que deve ser considerada
& OutroCampo1: Descrição para o outro campo 1
& OutroCampo2: Descrição para o outro campo 2
&**************************;***********;***********
&ID ;OutroCampo1;OutroCampo2
&- ;- ;-
&SSSSSSSSSSSSSSSSSSSSSSSSSS;IIIIIIIIIII;FFFFFFFFFFFF
DADO-UM-FUNCIONALIDADE-DOIS; 3; 3.0
DADO-UM-FUNCIONALIDADE-DOIS; 4; 4.0
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente a funcionalidade que deve ser considerada
& Campo1: Descrição para o campo 1
&**************************;**********
&ID ;Campo1
&- ;-
&SSSSSSSSSSSSSSSSSSSSSSSSSS;IIIIIIIIII
DADO-DOIS-FUNCIONALIDADE-UM; 1
DADO-DOIS-FUNCIONALIDADE-UM; 2
&**************************************************
& Descrição colunas:
&**************************************************
& ID: Identificador referente a funcionalidade que deve ser considerada
& OutroCampo1: Descrição para o outro campo 1
& OutroCampo2: Descrição para o outro campo 2
&**************************;***********;**************
&ID ;OutroCampo1;OutroCampo2
&- ;- ;-
&SSSSSSSSSSSSSSSSSSSSSSSSSS;IIIIIIIIIII;FFFFFFFFFFFFFF
DADO-DOIS-FUNCIONALIDADE-DOIS; 3; 3.0
DADO-DOIS-FUNCIONALIDADE-DOIS; 4; 4.0
Linhas descritivas e Réguas identificadoras dos campos¶
Nos exemplos acima, você deve ter percebido que há diversos registros iniciados com o caractere “&”. Como explicado anteriormente, estes registros não são lidos pelos modelos, portanto são opcionais. Ressaltamos, porém, que tais registros podem ser bastante úteis para descrever as informações que constam no arquivo e o conteúdo dos campos.
Em particular, uma “régua identificadora” do registro pode ser utilizada pelo usuário para indicar o tipo de dado a ser fornecido em cada campo, seguindo a convenção a seguir:
“S”: texto alfanumérico (string);
“I”: valor inteiro;
“F”: valor real (float)).
Ressalta-se que o alinhamento dos campos não é necessário, mas pode ser utilizado para os usuários que utilizam os arquivos texto para edição ou visualização. Por exemplo, se os registros mostrados anteriormente fossem escritos da forma a seguir, sem réguas e sem espaços entre os caracteres “;”:
DADO-UM-FUNCIONALIDADE-UM;1;1.0;Nome_Exemplo1
DADO-UM-FUNCIONALIDADE-UM;2;2.0;Nome_Exemplo2
DADO-DOIS-FUNCIONALIDADE-DOIS;3;3.0
DADO-DOIS-FUNCIONALIDADE-DOIS;4;4.0
os modelos iriam ler as informações da mesma forma que o exemplo “arquivo de dados para FUNCIONALIDADE-DOIS”. Em particular, esta maneira de informar os dados (sem espaços entre os campos) é até mais adequada para abertura do arquivo em editores de planilhas, pois evitam que surjam caracteres em branco no conteúdo das células
Interface gráfica (XLibs)¶
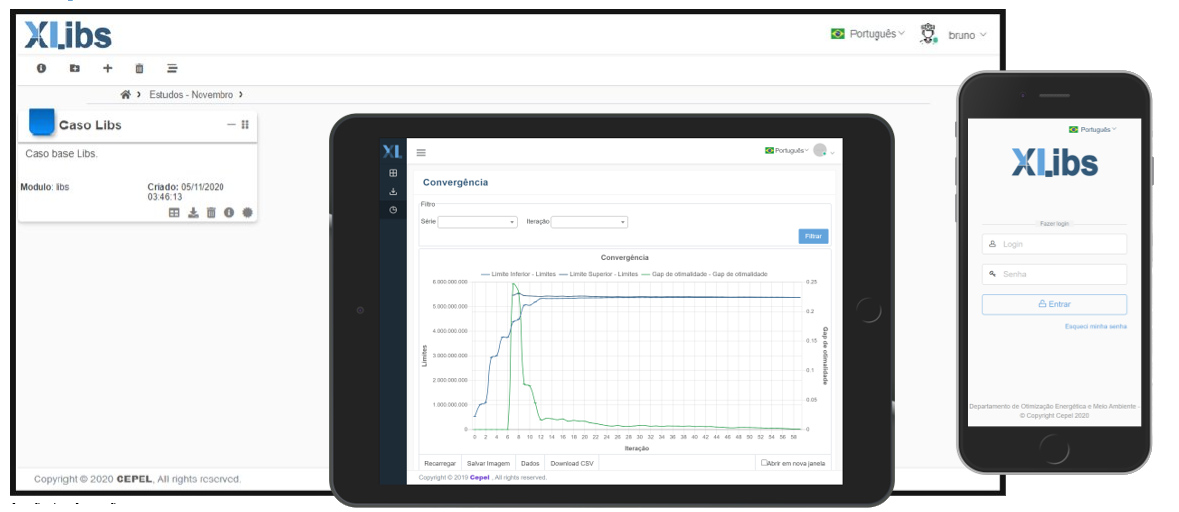
A interface gráfica do ambiente, chamada de “XLibs” está sendo desenvolvida em ambiente web, em um padrão atraente para o usuário e de forma responsiva, ou seja, voltada para utilização não só em desktops, como também em dispositivos móveis: tablets e smartphones. É a ferramenta indicada para usuários que buscam facilidade de edição e visualização dos dados de forma visual e dinâmica.
Desenvolvida de forma modular, a XLibs inclui está sendo concebida para incluir diversas ferramentas:
apresentação de dashboards com as informações mais relevantes para determinados casos executados;
módulo de controle de estudos e casos, sendo possível editar os dados e realizar execuções dos casos;
módulo para auxílio nas execuções dos casos de forma remota, ou seja, em servidores diferentes de onde a interface gráfica esteja instalada ou em nuvem;
módulo adicional para exibição e visualização dos resultados em formato tabular e gráfico;
ferramentas para controle de usuário, contratos e licenças.
Bibliotecas para integração com scripts¶
O Libs inclui bibliotecas integráveis com scripts personalizados dos usuários para manuseio de dados de entrada, execuções dos modelos e tratamento de resultados, permitindo customização e utilização dos resultados de uma rodada para reutilização como dados de entrada de rodadas posteriores.
Documentaçao em Formato Web¶
A documentação atual (manuais de metodologia e de usuário) dos modelos serão progressivamente migrados para o ambiente web (você está aqui agora!), podendo ser consultada de forma fácil e interativa, e sendo atualizada de forma contínua pelas equipes dos modelos. O conceito de padronização, adotado em todo o ambiente Libs, faz também com que a documentação seja voltada por funcionalidade e não por modelo, porém distinguindo, quando aplicável, as particularidades consideradas em cada aplicação. Além disso, os conteúdos dos manuais de metodologia e de usuário estarão unificados dentro de cada funcionalidade.
Informações adicionais¶
Além das características mencionadas, o ambiente conta com a internacionalização das ferramentas e com a possibilidade de incorporação de novos módulos específicos, sob demanda, para determinadas modelagens não pertinentes ao Sistema Interligado Nacional (SIN).